What makes Veda’s data so great?
Healthcare provider data can be riddled with inaccuracies—just ask anyone who uses network directories to find an in-network specialist or view clinics in a 10-mile radius. The Centers for Medicare & Medicaid Services (CMS) Medicare Advantage (MA) online provider directory reviews between September 2016 and August 2017 found that 52.2% of the provider directory locations listed had at least one inaccuracy.

Health tech companies have attempted to solve provider data inaccuracy problems with a number of products, platforms, and integrations. No solutions have been able to ultimately offer a better experience for members where it matters: the ability to easily book an appointment armed with accurate information.
Many solutions in the market focus on gathering all data sources available to identify providers but don’t have the ability to clean up those databases so they have only current and accurate information. A patient might find a doctor in a directory but if the location and coverage information was wrong, they still can’t make an appointment.
Enter Veda’s latest offering: Vectyr Data Curation. Vectyr offers the most up-to-date, comprehensive, and accurate source of provider data on the market. Vectyr’s database uses more than 100,000 unique sources to create an optimal collection of provider information. The data is continuously monitored, validated daily, and backed by our accuracy guarantees.
Prove It
How does Veda back up claims of accuracy and completeness? For one, our team of data scientists behind the development of Vectyr has the clout and expertise needed for intensive data modeling. From creating ground-breaking machine learning code to researching at the largest particle physics laboratory in the world, the best in science and technology are found at Veda. Here is how Veda employs a different approach than other data companies on the market:
- Automation: Veda fully automates static and temporal data, boosting accuracy and reducing provider barriers. This validation process is automated in real-time, a fundamental advantage for healthcare companies seeking effective data structure.
- Performance Measurement: Veda’s team of scientists carefully monitors the data’s success rate, creating statistical models, sample sizes, and methodologies to consistently guarantee accuracy. This process ensures specialty and data demands are evaluated and performing at the highest level.
- Data Reconciliation: As temporal data evolves, Veda’s entity resolution process follows. Our technology accounts for data drifts over time, so our entity resolution is calibrated to recognize correct data from the abundant sources available today. New data is always cleansed and standardized, then consolidated within a database to eliminate duplicates.
- Test Outcomes: Even with 95%+ accuracy, Veda doesn’t rely on automation to do all the work. The Veda team inspects all aspects of delivered data, including quality, delivery methods, bugs, and errors with a continuous monitoring process. By continually auditing and testing our data fields to confirm they are the competitive, current, and optimal quality we know reasonable coverage is reached.
Coverage, Precision, and Recall are numbers reported and recorded by the science team.
Coverage: What is the fraction of the data that isn’t blank?
Precision: When we do have an answer, how often is it right?
Recall: If we should have an answer, how often do we actually have it?
“Anyone can make an API. They are flashy, they can help operations, they can automate processes. But if your API is pulling in duplicative, inaccurate, and just plain bad information it’s useless,” says Dr. Robert Lindner, Chief Science & Technology Officer at Veda. “With our science backing, Veda’s data is guaranteed accurate and with flexible query so data delivery is where, when, and how users need it.”
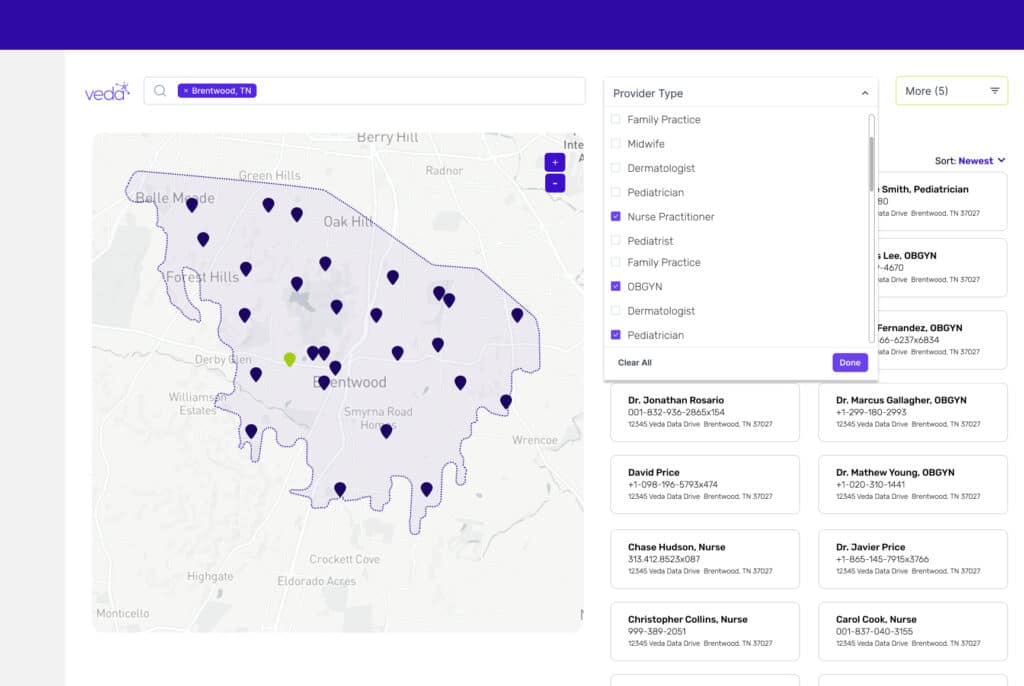
Veda’s data is currently being used by top health plans for the correction and cleansing of their directories. Now, customers, new prospects, and new channel partners have direct access to Veda’s best-in-class provider information based on their nuanced business use case.
Vectyr has profiles on more than 3.5 million providers who have an NPI 1 number—including MDs, DOs, RNs, social workers, DDS, and pharmacists.
What can health plans do with Veda’s data?
Staying atop changing information ensures provider directories are always accurate. This is no small feat as 20-30% of all provider directory information changes annually. With Vectyr, health plans can offer a better experience for members and providers by:
- Expanding network offerings: Members need both provider options and location access to get the care they need. Using Veda’s data can help health plans identify providers they aren’t currently contracted with and fill geographic or provider gaps in their network.
- Sourcing correct providers for referrals: Providing accurate and on-the-spot information for in-network referrals relieves administrative burdens and eliminates frustrating hours spent searching for answers.
- Quick credentialing: Credential providers faster and deliver faster onboarding and credentialing support with data that’s updated every 24 hours and guaranteed accurate.
What’s possible with optimal provider data?
There are immediate benefits to using Veda’s data. Health plan members will no longer wonder if their doctor of choice accepts their insurance or where the closest allergist to their home is. Hours of phone calls and administrative burdens are eliminated for both the member and the health plan. And, most importantly, health plans can trust Veda’s rigorous scientific validation methodology to ensure they have the optimal data for every provider in the country, on-demand, every day.
When health plans have access to optimal data, it means members have access to optimal data and that results in a markedly better customer experience.