Veda solves attestation problems by harnessing the power of AI and machine learning to automate manual data-gathering and validation processes
Attestation is necessary for compliance, but it fails to deliver quality provider data. At Veda, we’ve spent years measuring and monitoring the accuracy of attested data and its impact on quality—it just falls short. Attestation isn’t sufficient to achieve quality provider data.
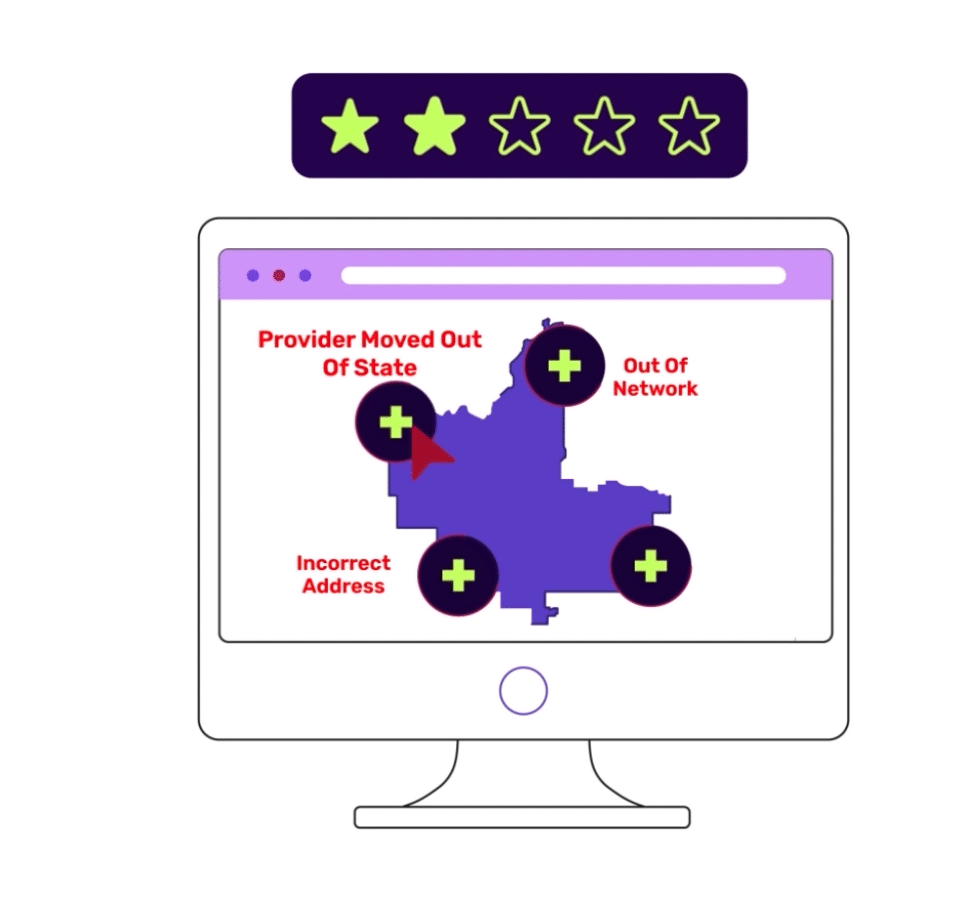
Attested data sources are updated slowly through manual workflows that are susceptible to human error, and some providers never update information at all. It doesn’t work well and requires providers to act outside their busy days just to attest. It’s abrasive and providers dislike the process.

The risk of error, and patient dissatisfaction, is high when attested data is the source. Take one recent “secret shopper” example from a senator in Oregon. His staff made over 100 calls to make an appointment with a mental health provider for a family member with depression at 12 Medicare Advantage insurance plans in six states. The callers could only get an appointment only 18% of the time. That means more than eight in 10 mental health providers listed in provider directories were inaccurate or weren’t taking appointments.
Attesting is so burdensome that smaller or private practices—like many in the psychiatric workforce—do not participate in health plan networks because of the administrative burden.
At Veda, we work to achieve member satisfaction and ease the administrative burden as our definition of accuracy is the same as health plan members—”Can I easily find the phone number to call and make an appointment with [X Doctor] at [X Location]?”
A Better Way to Source Quality Provider Data
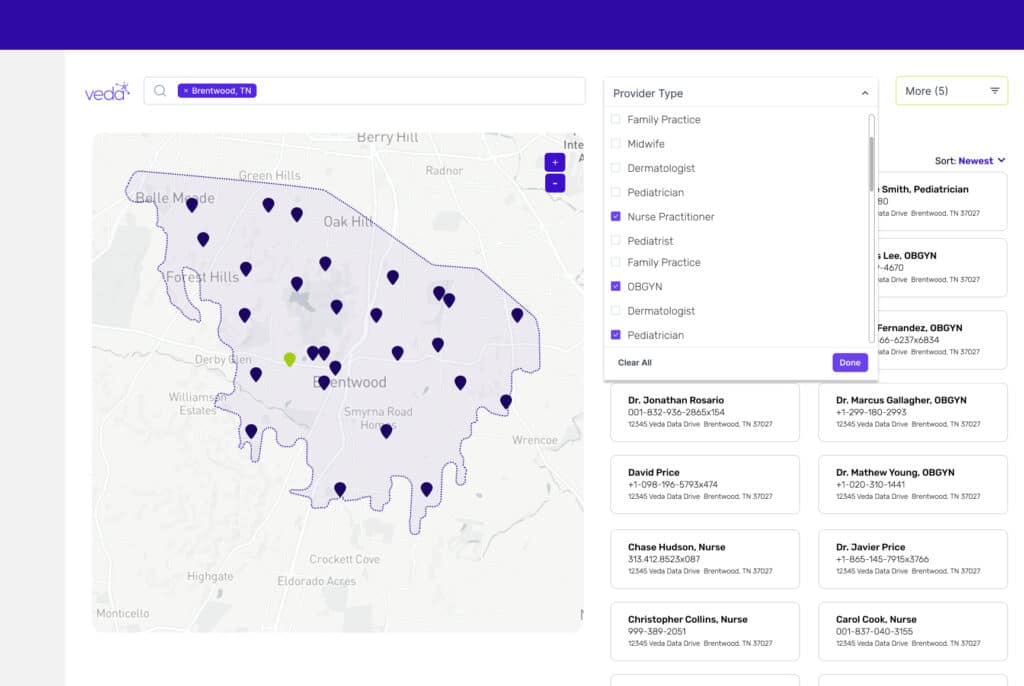
There is enough existing data to solve provider data accuracy problems, within current workflows, without relying on doctors to attest. We use the data providers generate every day, curated from over 100,000 unique sources, optimizing results for each provider, every 24 hours.
At Veda, we work to achieve member satisfaction and ease administrative burden as our definition of accuracy is the same as health plan members—”Can I easily find the phone number to call and make an appointment with [X Doctor] at [X Location]?”
Veda’s solutions are unique and proprietary. We employ rigorous scientific validation methodology to ensure we have optimal data for every provider in the U.S. on-demand, every day. Our comprehensive data set includes over 50 key data elements including demographic information; specialty & credentialing details; practice locations & group affiliation information; as well as contact information appropriate for making appointments. All without the attestation that isn’t sufficient for quality provider data.
Access To Comprehensive and Accurate Provider Data
We offer three unique products to address provider data challenges.
- Velocity Process Automation automates the manual effort of provider roster updates. Velocity applies predetermined business rules to unstructured and disorganized roster files to quickly compare incoming data to an existing directory, validate it against external data sources, and enhance it with critical missing data elements
- Quantym Data Quality Scoring analyzes entire provider directories, addressing the most at-risk data fields and identifying areas that may affect overall quality metrics.
- Vectyr Data Curation offers access to ready-to-query data to help manage overall provider and directory accuracy by filling gaps in missing or incorrect information with complete provider profiles. We provide these profiles for providers of multiple types, including physicians, nurses, allied health professionals, behavioral health specialists, pharmacists & dental providers.

The Impact of Bad Healthcare Data
The information included in provider directories changes often and the scope of required information keeps expanding. Practices move, physicians change practices, and contracts between practices and health plans expire. According to a report from CAQH and AMA, between 20% and 30% of directory information changes annually.
Yet, no single party is the exclusive keeper of this information. Some of the information is governed and controlled by the practice, such as contact information and the roster of clinicians who practice there. Other data, such as whether a clinician is accepting new patients under a specific plan, can be owned by the practice, the health plan, or in some instances, shared by both parties.
Only when data is accurate, timely and contextually relevant, can we make actionable decisions that positively impact patients.
In the health plan space, we saw that bad data was driving claims fallout, bad patient interactions, and sanctions. It was also impacting members of health plans who weren’t able to find the right doctor to access care, like in the case of the secret shopper experiment above.
Compliance is table stakes, which is why Veda doesn’t stop at getting the data right for the sake of CMS audits. Only when data is accurate, timely, and contextually relevant, can we make actionable decisions that positively impact patients.
In October 2022, CMS asked for public input in creating a national directory; a system in which it would collect information from providers and compile it into a single directory maintained by CMS. While an important undertaking, officials note there are many unanswered questions such as managing information for Medicare and private payers.
Luckily, provider directory problems are being solved right now by Veda’s innovative technology. Veda’s offerings are ushering in a new day where data is not a burden to doctors, nor an obstacle to patients. Innovative solutions already exist to connect individuals to the healthcare they so desperately need. All without the need for taxpayer dollars or the use of valuable CMS resources that could be dedicated to other deserving initiatives.
Our solution can mitigate the manual lift from multiple sources, and streamline the workflow with guaranteed accuracy and turnaround.
Having different authoritative sources depending on the data contributes to the difficulty of health plans and practices in keeping information accurate. Our solution can mitigate the manual lift from multiple sources, and streamline the workflow with guaranteed accuracy and turnaround.
The Veda Approach to Provider Data Quality
- Attestation-free: We don’t ask doctors to use portals or rely on attestation to validate.
- Evidence-Based Data: We utilize doctors’ current data usage to build evidence where they practice. The result? No human error and real-time updates.
- Higher-standard for Accuracy: Our definition of accuracy is the one members care about—”can you actually see this provider at this location?”
- Proven Methodology: Our roots are in science. We leverage the scientific method to understand and optimize performance.
- Unique, Patented Technology: Proprietary solution backed by five existing patents and more pending.
- Performance Amplification: Option to layer in your existing data—claims + live call audits—to optimize platform processing.
Guaranteed Outcomes
Speed and accuracy outcomes are defined in our SLAs and brand-defining for Veda. We stand by our data, unlike any others in the market.
Ready for high-quality provider data that is attestation-free? Request a free data assessment from Veda.