How to Find the Right Provider Data Vendor Partnership
It seems that almost every week we see new vendor offerings within the provider data management ecosphere—each claiming to offer a revolutionary way of visualizing your data and making impactful improvements for healthcare. The provider data accuracy challenges that health plans and provider organizations face are vast, so it’s not surprising that new health tech companies are quick to capitalize. Caution: all health tech companies may not be keeping new and developing AI regulations in mind when developing their technology.
All health tech companies may not be keeping new and developing AI regulations in mind when developing their technology.
Looking at the Bigger Provider Data Picture
Quality provider data can help the healthcare industry tackle some of the biggest challenges health plans and provider networks face, like onboarding, credentialing, roster creation, and referrals.
A commitment to improving your provider data can have great ROI potential and long-term impacts on your business and patient populations. But, with all the buzzwords and capability promises from the masses, how do you find the best vendor fit for your business needs?

Necessary Topics to Cover When Vetting Provider Data Vendors
To set you up for partnership success, here are discussion ideas for data vendor conversations:
- Find out the vendor’s practices for responsible data collection, storage, and validation. For example, does the vendor keep their data in the U.S.?
Veda’s Take: You want to ensure any vendor interacting with critical data is not utilizing offshore, 3rd party data processing centers that can unnecessarily expose data and therefore, providers’ information. Consider this: If patient data is protected from offshore processing vendors via HIPAA and other regulations, shouldn’t the same protections be afforded to provider data? Veda offers comprehensive security and data protection and is HITRUST-certified. - Understand the vendor’s business policies regarding AI. For example, how does an AI vendor utilize Language Learning Models?
Veda’s Take: Avoid risk by future-proofing your AI policies. Machine Learning can be a powerful tool, but should be approached thoughtfully and aligned with current and future U.S. legislative requirements such as President Biden’s executive order for the Development and Use of Artificial Intelligence. Warning: fewer companies comply with the proposed regulatory requirements than you may think. - Ask about their reporting and measurement. How does the vendor define accurate data and measure it during and after delivery?
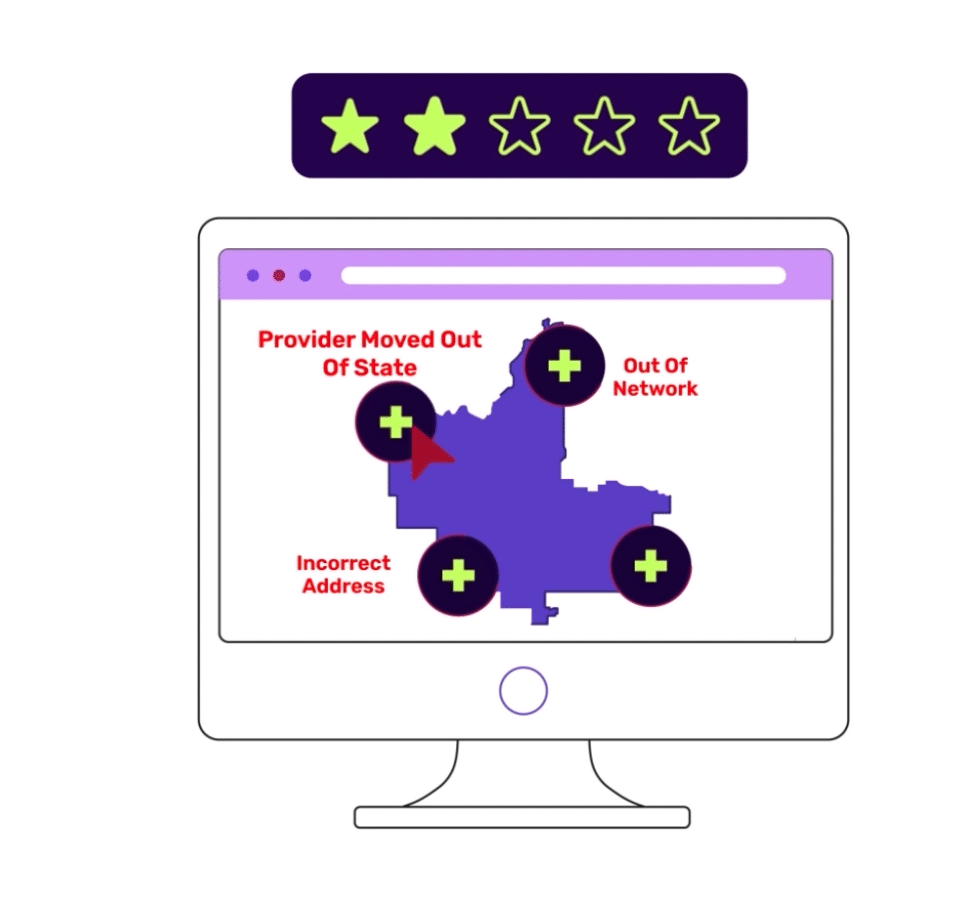
Veda’s Take: Data can be compliant but inaccurate and unusable for health plan members who depend on the data to get care. Be prepared to discuss your business goals and thresholds for accuracy—consider going beyond meeting regulatory guidelines. We think healthcare data should truly be considered “accurate” if it meets a member’s needs when accessing care. - Discuss what is necessary for your business success. Can the vendor offer the necessary tools to reach your goals and eliminate what is unproven?
Veda’s Take: Don’t be distracted by tools that may not deliver results or provide value for your goals. For example, APIs are often necessary to save time on automation. Therefore, many businesses focus on the ability to have an API connection and the API integration above even the results the product delivers. Or, in another example, the UX and the interface of a product can become a focal point above the actual functionality of the product. If you can’t trust the data and know how to interpret and use it, then connectivity and appearances don’t matter. - Determine what happens first. Can a vendor partner prioritize your specific business requirements?
Veda’s Take: All businesses have different objectives and these goals greatly impact priorities. Your vendor should clearly articulate what needs to happen first, upon implementation of the product, to realize immediate value and reach success. There is no one-size-fits-all solution when working with a provider data vendor. Before integration and during the initial conversations is the perfect time to establish an approach to prioritization within business rules. - Get familiar with the training process. What does the implementation, training, and delivery process look like for your AI data vendor?
Veda’s Take: How a provider data vendor plans to work with you, and how they plan to train others in your organization, is key to partnership success. Beyond day-to-day use of the tools, how does the vendor recommend using the data and applying the findings? Who should be trained on what tasks? Clear and concise preparation will ready everyone in your organization.
Ensure any vendor interacting with critical data is not utilizing offshore, 3rd party data processing centers that can unnecessarily expose data and therefore, providers’ information.
Once you have a solid understanding of how a potential partner tackles the above objectives, only then can you capitalize on a business case for building a collaborative partnership with a provider data vendor.

Need more ideas on what to ask a potential provider data vendor? See Veda’s Six Questions to Ask Your Provider Data Vendor.