The Centers for Medicare & Medicaid Services (CMS) regularly audits health plan programs and provider directories. All health plans providing services to Medicare and Medicare Advantage members are nearly guaranteed to be audited by CMS. By definition, the CMS directory accuracy audits aim to improve patient access and experience. Additionally, many standards for provider directories and network adequacy are developed based on CMS regulations.
Veda works with health plans to prepare for CMS audits and then interpret and address their audit results.
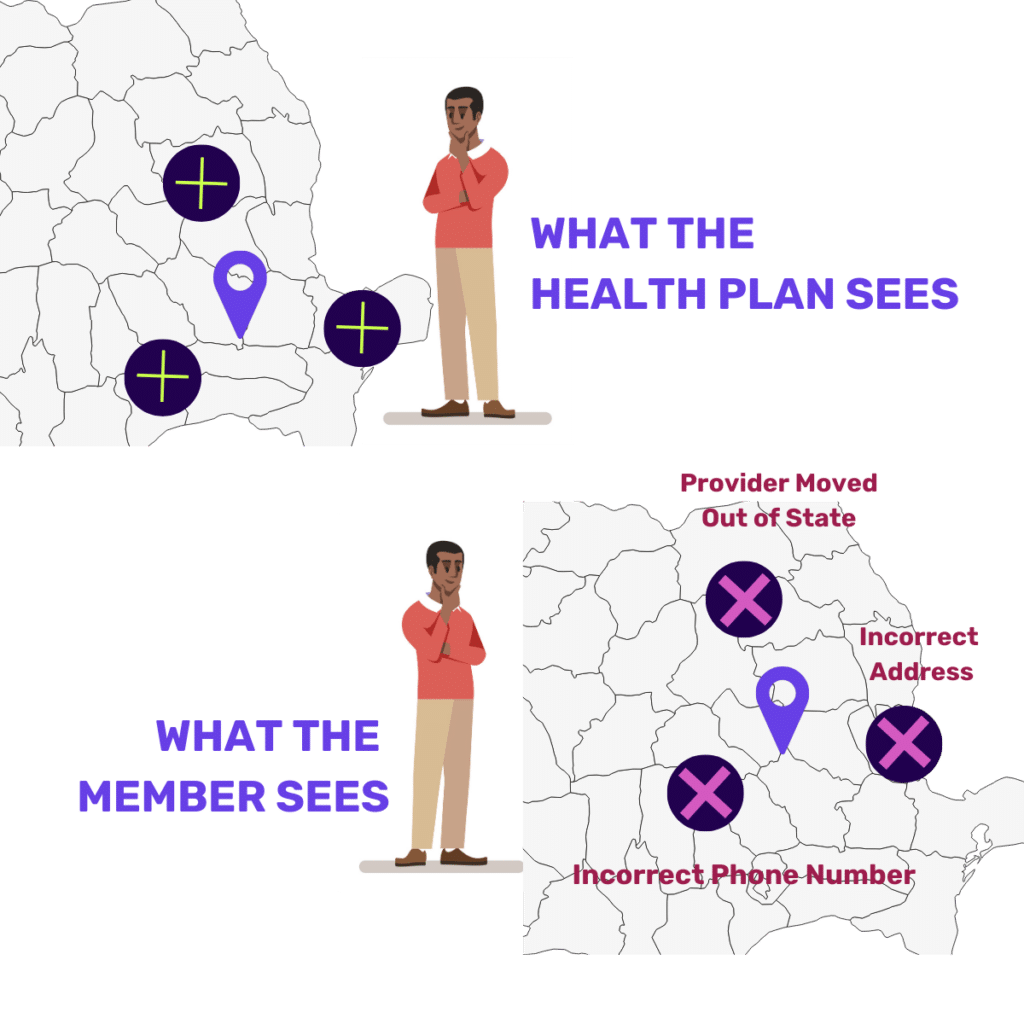
Unfortunately, health plans’ directory accuracy claims may not match with CMS’s findings—in the case of lower accuracy discovered, the plans may receive CMS sanctions and fines. Why are the directory accuracy rates differing and what can be done to reconcile the accuracy rates?
Why do accuracy rates determined by CMS and health insurance providers differ?

Many factors determine accuracy rates in provider directories. CMS zeroes in on specific fields (such as name, address, and phone number) for determining accuracy while insurance providers may go further in determining accuracy (such as specialty fields). Here are the reasons why updating directories while maintaining high accuracy levels—is an uphill battle:
- In anecdotes shared by those in the industry, 20–30% of providers are unresponsive during attestation requests. Attestation is not a sufficient data-collection tool and does not result in data quality.
- Many systems rely on heavily manual workflows, causing delays in data updates. Human error degrades data quality
- Provider abrasion and long turnaround times are present when constantly attesting to information
- Phone calls, even when used for verification, have a 20% variability rate. Meaning, if your call center has two people call the same provider twice in one day, you’ll get a different answer 20% of the time
Why Does CMS Audit Provider Directories?
A few years ago, a CMS Online Provider Directory Review Report looked at Medicare Advantage directories and found that 52% had at least one inaccuracy. The areas of deficiency included such errors as:
- The provider was not at the location listed,
- The phone number was incorrect, or
- The provider was not accepting new patients when the directory indicated they were.
And, despite provisions in the 2021 No Surprises Act legislation, new research has shown that directories remain inconsistent, one study citing “of the almost 450,000 doctors found in more than one directory, just 19% had consistent address and specialty information.” (Let alone complete accurate information including phone numbers.) The audits continually find inaccuracies as the years go on.
How Do Health Plans Prepare for CMS Audits?
Traditional approaches to audit preparation include phone calls and mock audits.
Phone Calls
Pricey and oftentimes inconsistent, call campaigns amount to hundreds of thousands of phone calls being made every day to check data.
Mock Audits
Mimics the audit experience with sample sets of small amounts of data but are not reflective of the overall directory.
These approaches are not sufficient for achieving successful audit results.
What Is CMS Looking for in Audits of Directories?
Not all information is equally important during an audit. The scoring algorithm assigns different weights for fields so if you’re starting somewhere, Veda recommends starting with the key areas of focus: Name, Address, Phone, Speciality, and Accepting Patients.
Addressing the most important data elements with quality validated data will move a health plan towards audit success.
How Veda’s Solutions Interpret and Address CMS Audit Results
CMS performs audits to advocate for members and better outcomes so interpreting audit results is the perfect place to get started with directory updates. Our research shows that when it comes to what members care about it is pretty simple: Choice, Accuracy, and Accessibility —meaning the ability to schedule, with their preferred provider, easily and quickly. On the first try.
Where to Start For CMS Audit Success
Many health plans are realizing that achieving directory accuracy and audit success is not a one-and-done. An ongoing surveillance approach is needed to confidently prepare and ultimately, achieve success in an audit.
Veda’s approach consistently evaluates the directory to provide ongoing insights. For example, we leverage technology to identify and prioritize providers for updates who haven’t attested recently, to ensure they have a data trail that supports their current status and information in a directory. By prioritizing bad data, this audit strategy is efficient and effective.
Diagnose your provider directory and fix critical data errors ahead of CMS audits with Veda.